Spiking Neural Networks (SNNs), known for their event-driven, low-power-consumption characteristics, are highly suitable for deployment in edge computing scenarios such as autonomous driving and mobile healthcare. However, in practical applications, due to the presence of scene bias in user data, pre-trained SNN models often struggle to adapt directly to personalized tasks. While on-device training is considered a viable solution, achieving efficient, low-power training on resource-constrained edge hardware remains a significant challenge.
Addressing these issues, Prof. Shang’s group at the State Key Laboratory of Fabrication Technologies for Integrated Circuits and the Institute of Microelectronics of the Chinese Academy of Sciences (IMECAS) has realized high-energy-efficiency training for edge-side Spiking Neural Networks in small-batch learning scenarios through algorithm and hardware co-design.
This work proposes a hardware-friendly training algorithm—Spiking Direct Feedback Alignment (SDFA)—which establishes direct feedback paths during error backpropagation. The feedback weights in this algorithm are implemented using fully random matrices that remain fixed throughout training, requiring no updates, thereby significantly reducing computational and memory overhead. At the hardware level, the team designed an efficient memristor-based in-memory computing architecture named PipeSDFA, which fully leverages the algorithmic features of SDFA to achieve three-level pipeline parallelism across time steps, data, and batch processing. This architecture also utilizes the intrinsic randomness of memristive devices to efficiently store the fixed random feedback matrices. To further enhance computational energy efficiency, this work introduced an input data reuse mechanism and proposed an efficient weight mapping scheme (vw-SDK), effectively optimizing the utilization of computational resources.
Experimental results show that the SDFA algorithm maintains model accuracy comparable to baseline methods on several datasets, with a loss not exceeding 2%. In terms of hardware performance, the PipeSDFA architecture achieves a 1.1x to 10.5x improvement in computational speed and a 1.37x to 2.1x enhancement in energy efficiency ratio compared to existing RRAM-CIM architectures (such as PipeLayer).
These results effectively address the hardware efficiency bottleneck in edge device training, providing a scalable solution for the practical application of neuromorphic computing systems in resource-constrained environments.
This study was presented as an oral report titled “When Pipelined In-Memory Accelerators Meet Spiking Direct Feedback Alignment: A Co-Design for Neuromorphic Edge Computing” at the 44th IEEE/ACM International Conference on Computer-Aided Design (ICCAD) held in Munich, Germany on Oct. 26-30, 2025. IMECAS postgraduate student Ren Haoxiong and Prof. Dashan Shang are the first and corresponding authors, respectively. This work was supported by the National Key R&D Program of China, the National Natural Science Foundation of China, and the Chinese Academy of Sciences.
The International Conference on Computer-Aided Design (ICCAD), co-sponsored by the Association for Computing Machinery (ACM) and the Institute of Electrical and Electronics Engineers (IEEE), is one of the premier and long-standing top-tier academic conferences in the fields of Electronic Design Automation (EDA) and integrated circuit design globally. The conference focuses on cutting-edge directions such as chip design automation, in-memory computing, and AI architecture, attracting extensive attention from top research teams and semiconductor companies worldwide.
Article Link: https://doi.org/10.1109/ICCAD66269.2025.11240745
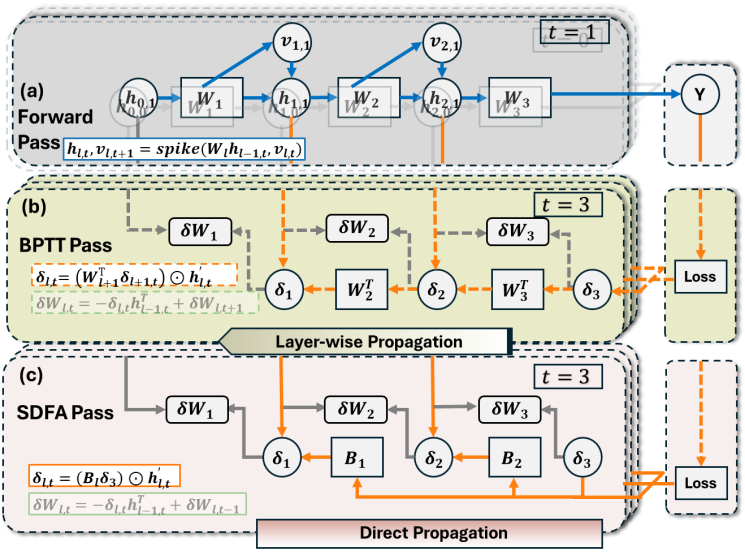
Fig. 1 Data dependency of backpropagation (BP) vs. direct feedback alignment (DFA) in training process of artificial neural networks
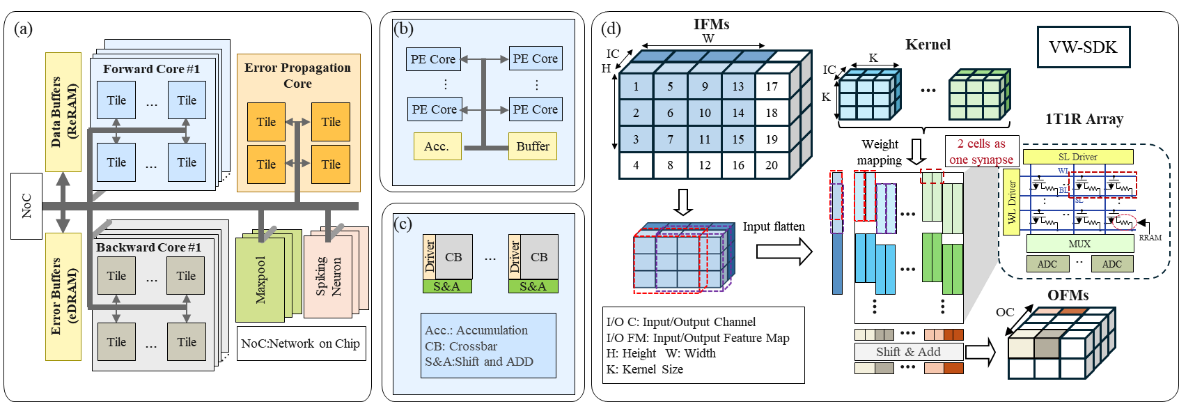
Fig. 2 The hierarchy of PipeSDFA. (a) Architecture level design with NoC, buffers and computational cores. (b) Tile level design with PE Cores. (c) PE level design with crossbars. (d) vw-SDK weight mapping strategy.










